
1. Introduction
시계열 예측은 에너지 소비, 교통 및 경제 계획, 날씨 예보, 질병 전파 예측 등 다양한 실제 응용 분야에서 중요한 역할을 합니다. 이러한 응용 분야에서는 장기적인 예측이 특히 중요한데, 이는 장기 계획과 조기 경고에 필수적이기 때문입니다. Transformer 기반 모델은 시계열 데이터의 장기 의존성을 모델링하는 데 강력한 성능을 보이지만, 복잡한 장기 패턴과 계산 효율성 문제로 인해 기존 모델들은 한계를 가집니다. 이 논문에서는 Auto-correlation, Decomposition을 이용해서 좋은 성능을 이끌어 냈습니다.
2. Related work
Models for Time Series Forecasting
시계열 예측을 위한 다양한 모델들이 개발되었습니다. ARIMA 모델은 비정상적인 프로세스를 정상 프로세스로 변환하여 예측 문제를 해결합니다. 필터링 방법과 재귀 신경망(RNN) 모델, LSTM 및 CNN 기반 모델들도 시계열 예측에 사용됩니다. Transformer 기반 모델들은 Self-attention machanism을 사용하여 시퀀셜 데이터를 강력하게 처리하지만, 계산 복잡도와 정보 활용에 한계를 가지고 있습니다.
Decomposition for time series
이전부터도 시계열 분해는 시간 시퀀스를 여러 구성 요소로 분해하여 예측 정확도를 향상시키는 표준 방법은 있었습니다. 기존의 방법들은 주로 과거 데이터를 기반으로 분해를 수행하고 이를 입력으로 사용하지는 않지만 Autoformer는 이를 예측 모델 내부의 블록으로 활용하여 예측 성능을 향상시킵니다.
3. Autoformer
3.1 Decomposition architecture
Autoformer는 Transformer를 분해 아키텍처로 개조한 모델입니다. 내재된 시계열 분해 블록과 Auto-Correlation 메커니즘을 포함하며, 예측 중간 결과에서 장기적인 트렌드를 점진적으로 추출하고 정제할 수 있습니다. 시계열 분해 블록은 시계를 트렌드-주기적 및 계절적 부분으로 분리하여 복잡한 시간 패턴을 처리합니다.
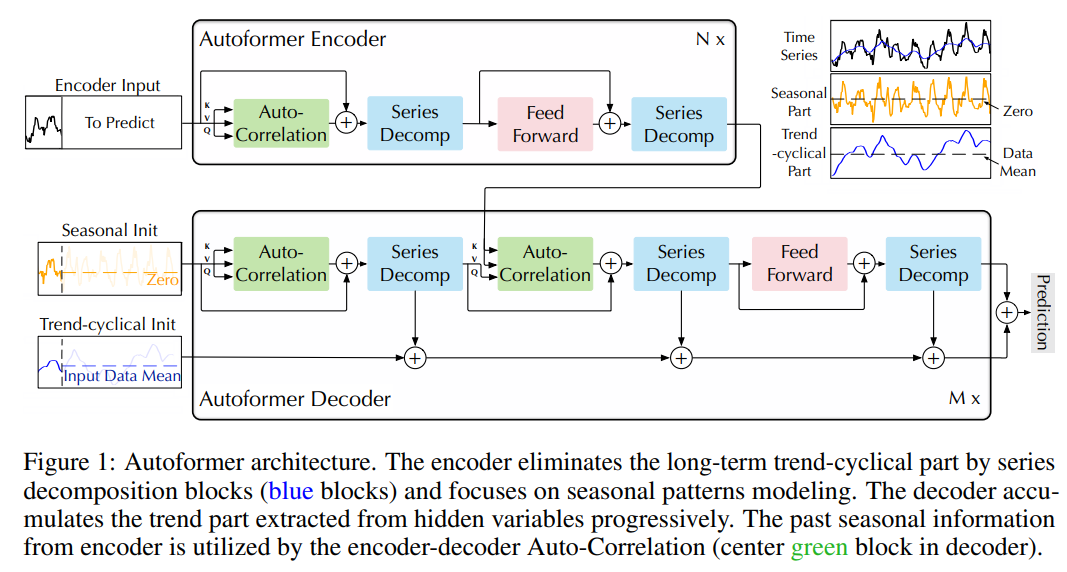
- 위 사진은 전체 구조이지만 먼저 Decomposition에 대해서 확인해보면, 전체 데이터의 분해는 Trend, Season, Residual로 이루어져있고, 쉽게 생각하면 Trend는 전체의 경향성, Season은 Trend안에서의 주기성, Residual은 약간의 랜덤성이라고 생각해주시면 됩니다. 저희가 학습할 내용은 Trend, Season을 학습해 좋은 성능을 얻어내는 것입니다.
- Trend, Season의 Decomposition 방법
- Xs=X−Xt,X_s = X - X_t,
- 이 부분에서 Model의 Input에 대해 자세하게 확인해보고 싶다면, 논문을 참조하시면 좋을 것 같습니다.
3.2 Auto-Correlation 메커니즘
Auto-Correlation은 시리즈 자기 상관을 계산하여 주기 기반 의존성을 발견하고, Time lags 집계를 통해 유사한 하위 시계를 집계합니다. 이는 Self-attention machanism을 대체하며, 시리즈 수준에서 정보 집계를 수행하여 계산 효율성과 정보 활용도를 높입니다.

- 여기서 신호처리와 관련된 증명이 등장하며 저 역시 이해하지 못한 부분이 많기에 단순하게 논문의 논리 흐름만 설명하게 디테일한 증명은 논문을 참조 부탁드립니다.
- 기존의 Self-attention block은 Time series에서 관련성 높은 점을 확인하기 위함이였다. 다만 이러면 주기성을 정확하게 예측하기 쉽지 않은 문제가 발생한다. 따라서 관련성 높은 주기를 찾기 위해 Auto-correlation 방법을 이용한다.

- 다만 기존 데이터로 Auto-correlation은 계산 복잡도에서 얻는 이득이 없다. 하지만 푸리에 변환(FFT)을 이용해 데이터를 Frequency data로 변환한다면 Wiener-Khinchin theroem에 의해 더 적은 계산 복잡도로 Auto-correlation이 계산이 가능하다.
- 따라서 이것이 데이터를 FFT를 통해 변환하고 다시 역 푸리에 변환 계산이 들어가는 이유이며 이에 대한 자세한 내용은 논문을 확인 부탁드립니다.
4. Experiments
4.1 Main results
다변수 설정의 경우, Autoformer는 모든 벤치마크 및 예측 길이 설정에서 일관되게 최고의 성능을 달성했습니다. 특히, ETT, 전기, Exchange, 교통, 날씨 데이터셋에서 기존 모델들보다 상당한 MSE 감소를 보였습니다. 단변수 설정에서도 Autoformer는 명확한 주기성을 가진 데이터셋과 주기성이 명확하지 않은 데이터셋 모두에서 뛰어난 성능을 보였습니다.
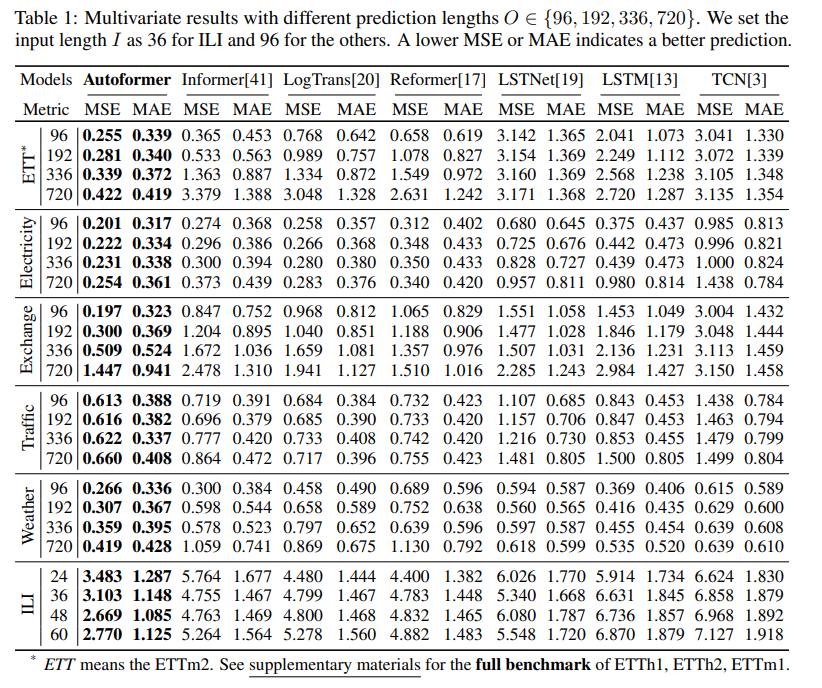

4.2 Model Analysis
시계열 분해: 시계열 분해 블록이 없는 경우 예측 모델은 계절적 부분의 증가 추세와 피크를 포착할 수 없습니다. 분해 블록을 추가함으로써 Autoformer는 시리즈에서 Trend-Series 부분을 점진적으로 집계하고 정제할 수 있습니다.

- 의존성 학습: Auto-Correlation이 학습한 시간 지연 크기는 가장 가능성이 높은 주기를 나타내며, 주기성을 기반으로 하위 시계열 간의 의존성을 찾습니다.

- 복잡한 계절성 모델링: Autoformer가 깊은 표현에서 학습한 지연은 원시 시계열의 실제 계절성을 나타낼 수 있습니다. 이는 실제 시나리오의 주기와 일치하며, Autoformer가 실제 시계열의 복잡한 계절성을 포착하고 해석 가능한 예측을 제공할 수 있음을 보여줍니다.
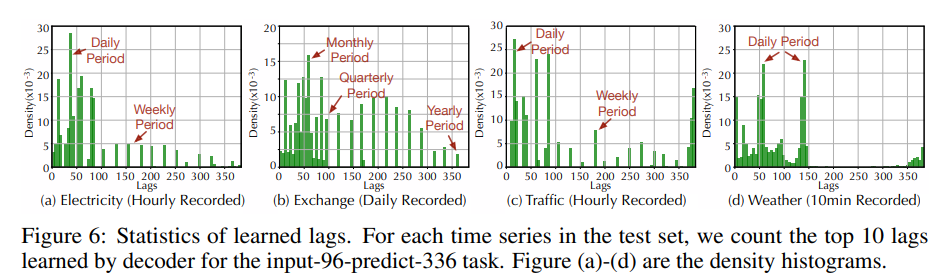
- 효율성 분석: Autoformer는 메모리와 시간 모두에서 O(L logL) 복잡도를 나타내며, 장기 시퀀스의 효율성을 향상시킵니다.

- Ablation Study
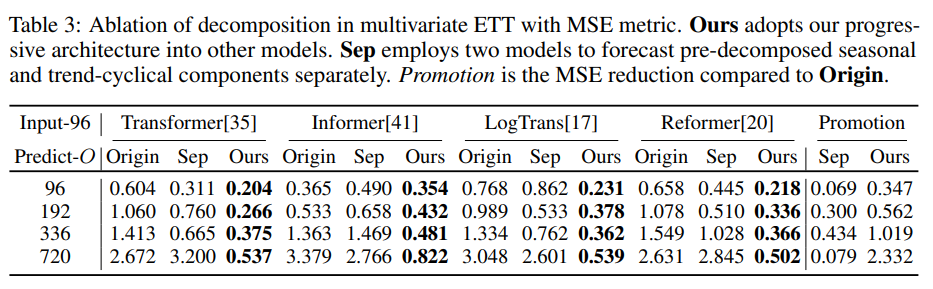

5. Conclusions
Autoformer는 시계열의 장기 예측 문제를 해결하기 위해 Decomposition architecture과 Auto-Correlation 메커니즘을 도입했습니다. 이는 복잡한 패턴을 처리하고 정보 활용도를 높이는 데 효과적입니다. Autoformer는 광범위한 실제 데이터셋에서 일관된 최첨단 성능을 보여주며, 장기 예측의 새로운 표준을 제시합니다.
참고자료
1. https://proceedings.neurips.cc/paper/2021/hash/bcc0d400288793e8bdcd7c19a8ac0c2b-Abstract.html
Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting
Requests for name changes in the electronic proceedings will be accepted with no questions asked. However name changes may cause bibliographic tracking issues. Authors are asked to consider this carefully and discuss it with their co-authors prior to reque
proceedings.neurips.cc
2. https://www.youtube.com/watch?v=SyEzISYGeg4