
Introduction
시계열 예측은 다양한 도메인에서 중요한 역할을 합니다. 특히, 긴 시퀀스 시계열 예측(LSTF)은 모델의 높은 예측 능력을 요구합니다. Transformer 모델은 긴 종속성을 포착하는 데 우수한 성능을 보이지만, 계산 복잡도와 메모리 사용량이 커 LSTF에 적용하는 데 어려움이 있습니다. 본 논문에서는 이러한 문제를 해결하기 위해 Informer를 제안합니다.

> 여기서 저자는 Long sequence에 대한 정의를 48개 이상의 출력물을 내는 것을 의미한다고 정의하며 시작합니다. 이는 LSTM에서 MSE의 값이 늘고, Inference speed가 급격히 줄어드는 기준으로 설정한 것임을 확인할 수 있습니다.
Transformer의 한계
Vanilla Transformer는 세 가지 주요 한계를 가지고 있습니다:
- 자기 주의의 제곱 계산으로 인한 높은 시간 복잡도.
- 긴 입력에 대한 레이어 스택의 메모리 병목 현상.
- 긴 출력 예측 시 속도 저하.
여러 연구들이 Self attention machanism의 효율성을 개선하기 위해 시도했습니다. Sparse Transformer, LogSparse Transformer, Longformer는 모두 제곱 계산 문제를 해결하기 위해 휴리스틱 방법을 사용하여 Self attention machanism 의 복잡도를 O(L \log L)로 줄였습니다. 그러나 이러한 방법들은 Vanilla transformer의 첫 번째 문제에 대한 이점만 가지며, 긴 시퀀스 예측에서 중요한 메모리 병목 현상과 속도 저하 문제는 해결되지 않았습니다.
Contribution
본 논문의 주요 Contribution은 다음과 같습니다:
- ProbSparse Self attention machanism을 통해 Transformer의 시간 복잡도와 메모리 사용량을 줄였습니다.
- Self attention distilling operation를 통해 긴 시퀀스 입력을 효율적으로 처리할 수 있도록 했습니다.
- Generative style 디코더를 통해 긴 시퀀스 예측의 추론 속도를 크게 향상시켰습니다.
Preliminary
문제 정의
우리는 먼저 LSTF 문제 정의를 제공합니다. 고정 크기 윈도우로 롤링 예측 설정 하에서, 입력 Xt={xt1,...,xtLx}X_t = \{x_{t1}, ..., x_{tL_x}\}는 시간 t에서, 출력은 해당 시퀀스 Yt={yt1,...,ytLy}Y_t = \{y_{t1}, ..., y_{tL_y}\}를 예측하는 것입니다. LSTF 문제는 이전 작업보다 더 긴 출력 길이 L_y를 장려하며, 특징 차원이 단일 변수 사례에 국한되지 않습니다(dy≥1d_y \geq 1).

- 여기서 Positional encoding에 관한 추가적인 내용이 나옵니다. 기존의 Positional encoding 뿐만 아니라, Day, Month, Hoilday와 같은 Global time stamp가 들어갑니다.
Methodology
시계열 예측을 위한 기존 방법은 크게 두 가지 범주로 나눌 수 있습니다. 고전적인 시계열 모델은 시계열 예측을 위한 신뢰할 수 있는 작업을 수행하며, 딥 러닝 기술은 주로 RNN과 그 변형을 사용하여 인코더-디코더 예측 패러다임을 개발합니다. 우리의 제안인 Informer는 인코더-디코더 아키텍처를 유지하면서 LSTF 문제를 해결합니다.
Efficient Self-attention Machanism
Canonical Self-attention는 쿼리, 키, 값으로 구성된 입력을 기반으로 정의되며, Scaled-dot product를 수행합니다. 기존의 시도는 Self-attention probability의 잠재적 sparsity을 밝혀내어 성능에 크게 영향을 미치지 않고 "Selective" 집계 전략을 설계했습니다.
> 여기서 반드시 알아야할 내용들이 2가지 나옵니다. 첫 번째는 Self-attention에 Sparsity가 있다. 두 번째는 그 중에서 어떤 것을 고를 것인가?에 대한 내용입니다. 일단 첫 번째 Self-attention에서 attention-score matrix를 시각화한 모습을 보시면

> 다음과 같이 sample이 점점 증가할 수록 softmax score의 평균이 굉장히 낮아지는 것을 알 수 있습니다. 보시면 거의 0에 수렴하고 있습니다. 따라서 모든 attention score가 의미있는 것은 아니기에 이를 해결해보고자 합니다. 그리고 이를 Selective한 과정을 통해 의미있는 attention score를 찾아내려고 햇던 이전 과정들에 대해서 설명합니다.
- Sparse Transformer (2019)
- Log Sparse Transformer (2019)
- Long former (2020)
> 다만 이러한 도전들은 정말 의미있는 attention score을 목표로 찾은 것이 아닌 랜덤 혹은 일정한 윈도우에서 찾은 내용이라 저자는 이것보다는 좋은 방법을 제시해보겠다고 하며 다음 챕터로 넘어갑니다.
Query Sparsity Measurement
간략하게 설명하자면 기존 쿼리-키에 대한 Attention을 특정한 Uniform 분포와 차이가 있기에 이 두개의 분포를 쿨백 라이블러 발산(두 확률분포의 차이를 확인하는 법)을 이용해 Uniform 분포와 많이 다른 값을 찾으면 그 값이 Prominant attention으로 볼 수 있다는 내용입니다. 이에 관해서는 많은 Equation이 있고, 증명 역시도 있으나 제가 하고자 하는 취지랑 벗어나기에 자세한 설명을 갖춘 다른 참고자료를 남겨놓겠습니다. 관심이 있으신 분들은 한번 보시면 좋을 것 같습니다. https://velog.io/@suubkiim/Paper-Review-Informer-Beyond-Efficient-Transformer-for-Long-SequenceTime-Series-Forecasting
[Paper Review] Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting
Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting Transformer를 기반으로 long sequence의 시계열 예측을 수행하는 모델
velog.io
ProbSparse Self-attention
방금 전 방법에 기반하여, 각 키가 prominant한 상위 u개의 쿼리에만 뽑아서 ProbSparse Self-attention를 구현합니다. 이 메커니즘은 O(\log L_Q) dot-product를 계산하고 레이어 메모리 사용량은 O(L_K \log L_Q)를 유지합니다. 여기서도 위와 같이 실제로 Self-attention을 구하지 않고 근사값으로 쓸 수 있는 다른 방식을 이용함을 알 수 있습니다.
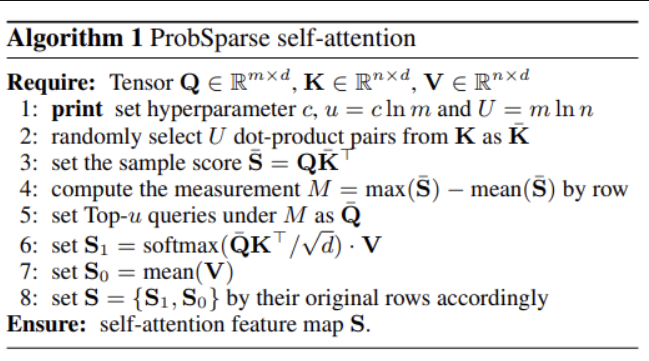
Self-attention distilling
ProbSparse 자기 주의 메커니즘의 자연스러운 결과로, 인코더의 특징 맵에는 값 의 중복된 조합이 포함됩니다. 우리는 다음 레이어에서 지배적인 특징을 가진 상위 주의를 강조하여 집중된 자기 주의 특징 맵을 만들기 위해 증류 작업을 사용합니다.
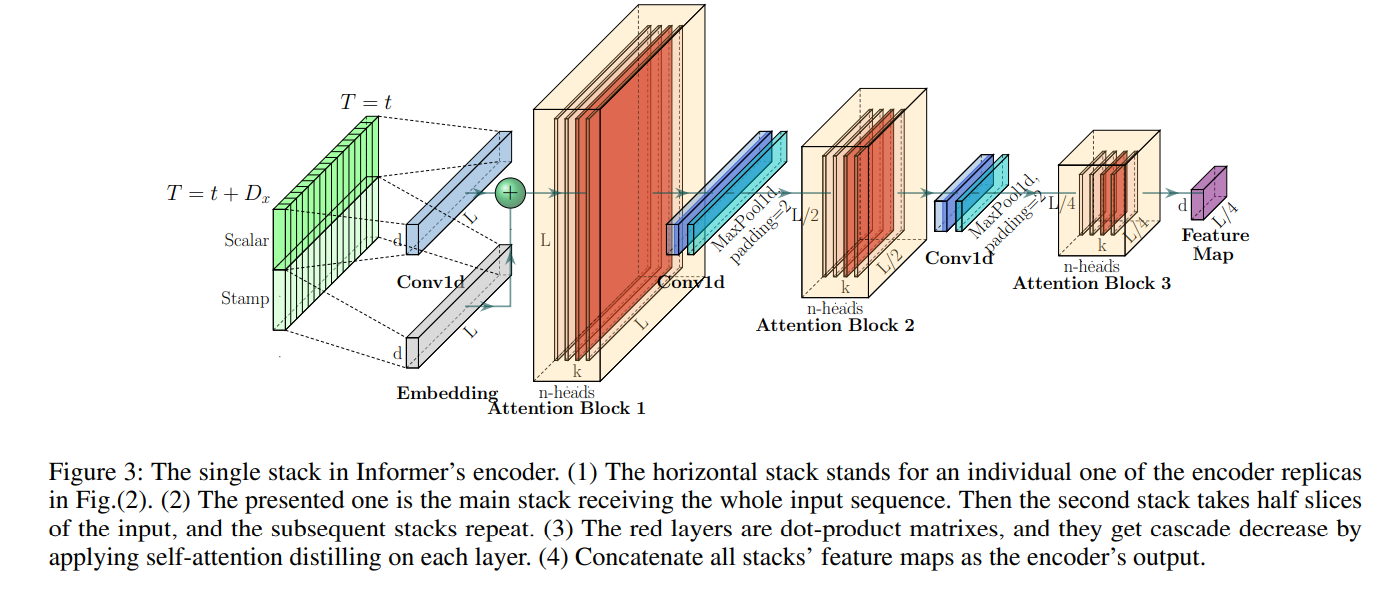
> 여기서 빨간색의 Attention Block이 점점 작아지는 모습을 확인할 수 있는데, 이게 Self-attention distilling 과정이며 마치 Convolution에서 feature map을 줄이는 것과 같다고 생각하시면 될 것 같습니다.
+ 추가적인 내용으로는 여기서 Encoder의 Robust를 증가시키기 위한 방법이 제시되고 있습니다.
Generative Style Decoder
기본 디코더 구조를 사용한다면 Step by step Inference를 하게 됩니다. 이는 출력값을 입력값으로 다시 사용하게 되면서 생기는 문제인데, 이 논문에서는 그렇게 하지 않고 애초에 Decoder에 들어갈 입력에다가 Target 시점의 앞 부분을 입력으로 넣고 뒤의 마치 padding과 같은 값을 넣어줍니다. 다만 이 padding은 positional embedding이 되어있는 값이 들어가기에 완전히 비어있는 값은 아님을 알고 있어야합니다.
Experiments
실험 결과
단변량 및 다변량 시계열 예측 설정에서 Informer 모델이 다른 방법보다 우수한 성능을 보임을 확인합니다.
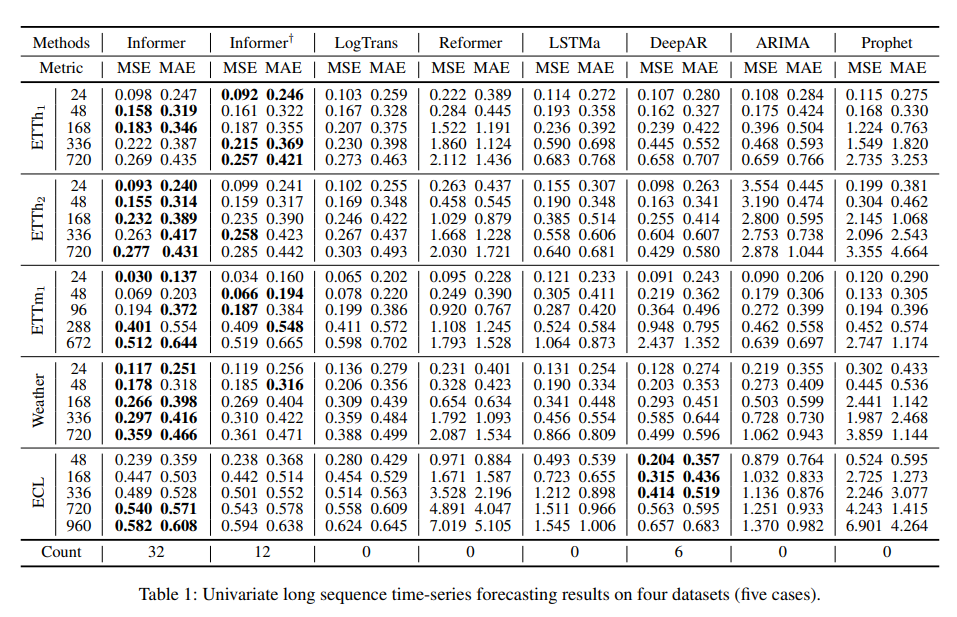
- 데이터 셋 옆의 24, 48, 168는 예측 Sequence의 길이입니다.
- ECL 데이터에서는 상대적으로 짧은 길이에서는 DeepAR이 우수한 성능을 보이기도 했으나 길이가 길어짐에 따라 Informer가 우세한 성능을 보였습니다.
- Informer† 는 Informer에서 Prop sparse attention을 canonical attention으로 대체한 모델입니다.
Conclusion
본 논문에서는 긴 시퀀스 시계열 예측 문제를 해결하기 위해 Informer를 제안했습니다. ProbSparse Self-attention machanism과 Self-attention distilling을 통해 Transformer의 시간 복잡도와 메모리 사용량 문제를 해결했으며, Generative Style Decoder를 설계하여 기존 인코더-디코더 아키텍처의 한계를 완화했습니다. 실험 결과, Informer는 LSTF 문제에서 우수한 예측 능력을 보였습니다.
참고자료
[Paper Review] Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting
Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting Transformer를 기반으로 long sequence의 시계열 예측을 수행하는 모델
velog.io
2. https://github.com/zhouhaoyi/Informer2020/tree/f22f199faa2943731de183ad66f478ca4eb3748e
GitHub - zhouhaoyi/Informer2020: The GitHub repository for the paper "Informer" accepted by AAAI 2021.
The GitHub repository for the paper "Informer" accepted by AAAI 2021. - zhouhaoyi/Informer2020
github.com